क्लाउड कम्प्यूटिंग और बिग डेटा के बीच अंतर

विषय
- तुलना चार्ट
- क्लाउड कम्प्यूटिंग की परिभाषा
- बिग डेटा की परिभाषा
- क्लाउड कंप्यूटिंग और बिग डेटा के बीच संबंध
- निष्कर्ष
क्लाउड कंप्यूटिंग एक समेकित तरीके से काम करता है, और बड़ा डेटा क्लाउड कंप्यूटिंग के अंतर्गत आता है। क्लाउड कंप्यूटिंग और बिग डेटा के बीच महत्वपूर्ण अंतर यह है कि क्लाउड कंप्यूटिंग का उपयोग विशाल भंडारण क्षमता, (बड़ा डेटा) को संभालने के लिए किया जाता है, जो कंप्यूटिंग और स्टोरेज संसाधनों का विस्तार करता है। दूसरी तरफ, बड़ा डेटा और कुछ नहीं बल्कि असंरक्षित, निरर्थक और शोर डेटा और जानकारी का एक विशाल मात्रा है जिसमें से उपयोगी ज्ञान को निकाला जाना है। उपरोक्त फ़ंक्शन करने के लिए क्लाउड कंप्यूटिंग तकनीक डेटा की शानदार मात्रा से निपटने के लिए विभिन्न लचीले और तकनीक प्रदान करती है।
इसमें इनपुट, प्रोसेसिंग और आउटपुट मॉडल शामिल हैं जिन्हें नीचे समझाया गया है; आरेख क्लाउड कंप्यूटिंग और बड़े डेटा के बीच संबंधों को विस्तार से दिखाता है।
-
- तुलना चार्ट
- परिभाषा
- मुख्य अंतर
- निष्कर्ष
तुलना चार्ट
| तुलना के लिए आधार | क्लाउड कंप्यूटिंग | बड़ा डाटा |
|---|---|---|
| बुनियादी | एकीकृत कंप्यूटर संसाधनों और प्रणालियों का उपयोग करके ऑन-डिमांड सेवाएं प्रदान की जाती हैं। | इस पर काम करने के लिए पारंपरिक प्रसंस्करण तकनीक की मनाही, संरचित, असंरचित, जटिल डेटा का व्यापक सेट। |
| उद्देश्य | दूरस्थ सर्वर पर संग्रहीत और संसाधित किए जाने वाले डेटा को सक्षम करें और किसी भी स्थान से एक्सेस किया जाए। | छिपे हुए मूल्यवान ज्ञान को निकालने के लिए बड़ी मात्रा में डेटा और सूचना का संगठन। |
| काम कर रहे | वितरित कंप्यूटिंग का उपयोग डेटा का विश्लेषण करने और अधिक उपयोगी डेटा का उत्पादन करने के लिए किया जाता है। | क्लाउड आधारित सेवाओं को प्रदान करने के लिए इंटरनेट का उपयोग किया जाता है। |
| लाभ | कम रखरखाव खर्च, केंद्रीकृत मंच, बैकअप और वसूली के लिए प्रावधान। | लागत प्रभावी समानता, स्केलेबल, मजबूत। |
| चुनौतियां | उपलब्धता, परिवर्तन, सुरक्षा, चार्जिंग मॉडल। | डेटा विविधता, डेटा संग्रहण, डेटा एकीकरण, डेटा प्रोसेसिंग और संसाधन प्रबंधन। |
क्लाउड कम्प्यूटिंग की परिभाषा
क्लाउड कंप्यूटिंग हाई-स्पीड इंटरनेट का उपयोग करके किसी भी समय, कहीं से भी, किसी भी समय डेटा की किसी भी राशि को संग्रहीत और पुनर्प्राप्त करने के लिए सेवाओं का एक एकीकृत मंच प्रदान करता है। क्लाउड डेटा को स्टोर करने, प्रबंधित करने और संसाधित करने के लिए पूरे इंटरनेट में फैला हुआ स्थलीय सर्वर का एक व्यापक सेट है। क्लाउड कंप्यूटिंग को विकसित किया गया है ताकि डेवलपर्स वेब-स्केल कंप्यूटिंग को आसानी से लागू कर सकें। इंटरनेट के विकास ने क्लाउड कंप्यूटिंग मॉडल को पीसा है क्योंकि इंटरनेट क्लाउड कंप्यूटिंग की नींव है। क्लाउड कंप्यूटिंग को कुशलता से काम करने के लिए हमें हाई-स्पीड इंटरनेट कनेक्शन की आवश्यकता होती है। यह एक लचीला वातावरण प्रदान करता है, जहां क्षमता और क्षमताओं को गतिशील रूप से जोड़ा जा सकता है, और प्रति उपयोग रणनीति के अनुसार भुगतान किया जा सकता है।
क्लाउड कंप्यूटिंग में कुछ आवश्यक गुण हैं जो संसाधन पूलिंग, ऑन-डिमांड स्वयं-सेवा, व्यापक नेटवर्क एक्सेस, मापा सेवा और तेजी से लोच हैं। बादल चार प्रकार के होते हैं - सार्वजनिक, निजी, संकर और समुदाय।
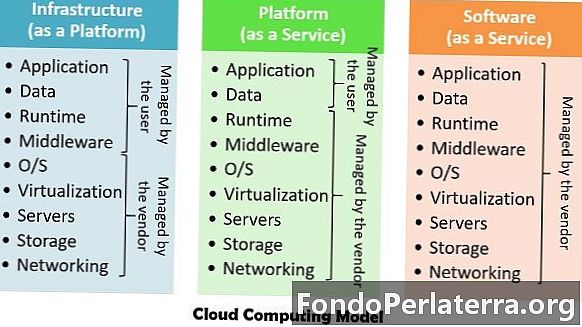
मूल रूप से तीन क्लाउड कंप्यूटिंग मॉडल हैं - प्लेटफ़ॉर्म एक सेवा (पास), एक सेवा के रूप में अवसंरचना (Iaas), एक सेवा (सास) के रूप में सॉफ़्टवेयर, जो हार्डवेयर के साथ-साथ सॉफ़्टवेयर सेवाओं का उपयोग करता है।
- सेवा के रूप में अवसंरचना - इस सेवा का उपयोग बुनियादी ढांचे को वितरित करने के लिए किया जाता है, जिसमें भंडारण प्रसंस्करण शक्ति और आभासी मशीनें शामिल हैं। यह सेवा स्तर समझौते (SLA) के आधार पर संसाधनों के वर्चुअलाइजेशन को लागू करता है।
- एक सेवा के रूप में मंच - यह IaaS लेयर के ऊपर आता है, जो उपयोगकर्ताओं को क्लाउड एप्लिकेशन को तैनात करने में सक्षम करने के लिए प्रोग्रामिंग और रन-टाइम वातावरण प्रदान करता है।
- एक सेवा के रूप में सॉफ्टवेयर - यह उन क्लाइंट को एप्लिकेशन डिलीवर करता है जो सीधे क्लाउड प्रोवाइडर पर चलते हैं।
बिग डेटा की परिभाषा
डेटा में बदल जाता है बड़ा डाटा आईटी सिस्टम की क्षमताओं से परे मात्रा, विविधता, वेग में वृद्धि के साथ, जो डेटा के भंडारण, विश्लेषण और प्रसंस्करण में कठिनाई उत्पन्न करते हैं। कुछ संगठनों ने इस प्रकार की संरचित डेटा की बड़ी मात्रा से निपटने के लिए उपकरण और विशेषज्ञता विकसित की है, लेकिन तेजी से बढ़ रही मात्रा और डेटा का तेज प्रवाह क्षमता को समाप्त कर देता है मेरी यह और तुरंत कार्रवाई योग्य बुद्धि उत्पन्न करना। यह स्वैच्छिक डेटा नियमित उपकरणों में संग्रहीत नहीं किया जा सकता है और वितरित वातावरण में बिखरा हुआ है। बिग डेटा कंप्यूटिंग की एक प्रारंभिक अवधारणा है डेटा विज्ञान जो बड़े पैमाने पर बुनियादी ढाँचे पर वैज्ञानिक खोज और व्यापार विश्लेषण के लिए बहुआयामी सूचना खनन पर ध्यान केंद्रित करता है।
बड़े डेटा के मूलभूत आयाम वॉल्यूम, वेग, विविधता और सत्यता हैं जो ऊपर दिए गए हैं, बाद में दो और आयाम विकसित किए गए हैं जो परिवर्तनशीलता और मूल्य हैं।
- आयतन - डेटा के बढ़ते आकार को दर्शाता है जो इसे संसाधित करने और संग्रहीत करने के लिए पहले से ही समस्याग्रस्त है।
- वेग - यह वह उदाहरण है जिसमें डेटा कैप्चर किया जाता है और डेटा के प्रवाह की गति।
- वैराइटी - डेटा हमेशा एक रूप में मौजूद नहीं होता है, डेटा के विभिन्न रूप होते हैं, उदाहरण के लिए -, ऑडियो, छवि और वीडियो।
- सच्चाई - यह डेटा की विश्वसनीयता के रूप में जाना जाता है।
- परिवर्तनशीलता - यह बड़े डेटा में निर्मित विश्वसनीयता, जटिलता और विसंगतियों का वर्णन करता है।
- मूल्य - सामग्री का मूल रूप बहुत उपयोगी और उत्पादक नहीं हो सकता है, इसलिए डेटा का विश्लेषण किया जाता है, और उच्च मूल्यवान डेटा की खोज की जाती है।
- क्लाउड कंप्यूटिंग इंटरनेट पर छितरी हुई कंप्यूटिंग संसाधनों का उपयोग करके मांग पर वितरित कंप्यूटिंग सेवा है। दूसरी ओर, बड़ा डेटा कंप्यूटर डेटा का एक विशाल सेट है, जिसमें संरचित, असंरचित, अर्ध-संरचित डेटा शामिल है जिसे पारंपरिक एल्गोरिदम और तकनीकों द्वारा संसाधित नहीं किया जा सकता है।
- क्लाउड कंप्यूटिंग उपयोगकर्ताओं को मांग के आधार पर सास, पेस और आईएएस जैसी सेवाओं का लाभ उठाने के लिए एक मंच प्रदान करता है और यह उपयोग के अनुसार सेवा के लिए शुल्क भी लेता है। इसके विपरीत, बड़े डेटा का प्राथमिक उद्देश्य डेटा के एक विनम्र संग्रह से छिपे हुए ज्ञान और पैटर्न को निकालना है।
- क्लाउड कंप्यूटिंग के लिए हाई-स्पीड इंटरनेट कनेक्शन आवश्यक है। जैसा कि, डेटा का विश्लेषण करने और मेरा उपयोग करने के लिए बड़े डेटा वितरित कंप्यूटिंग का उपयोग करता है।
क्लाउड कंप्यूटिंग और बिग डेटा के बीच संबंध
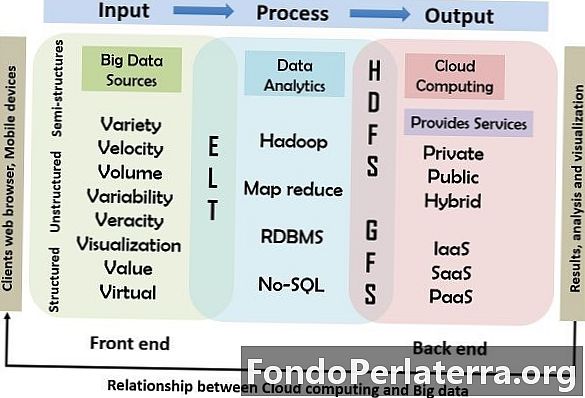
नीचे दिखाया गया आरेख बड़े डेटा के साथ क्लाउड कंप्यूटिंग के संबंध और कार्य को दिखाता है। इस मॉडल में, प्राथमिक इनपुट, प्रसंस्करण और आउटपुट कंप्यूटिंग मॉडल को एक संदर्भ के रूप में उपयोग किया जाता है जिसमें सिस्टम में माउस, कीबोर्ड, सेल फोन, और अन्य स्मार्ट उपकरणों जैसे इनपुट उपकरणों का उपयोग करके बड़ा डेटा डाला जाता है। प्रसंस्करण के दूसरे चरण में सेवाएं प्रदान करने के लिए क्लाउड द्वारा उपयोग किए जाने वाले उपकरण और तकनीक शामिल हैं। अंत में प्रसंस्करण का परिणाम उपयोगकर्ताओं को दिया जाता है।
निष्कर्ष
क्लाउड कंप्यूटिंग तकनीक बड़े डेटा के लिए उपयोग में आसानी, संसाधनों तक पहुंच, आपूर्ति और मांग पर संसाधन के उपयोग में कम लागत और बड़े डेटा को संभालने में उपयोग किए जाने वाले ठोस उपकरणों के उपयोग को कम से कम करने के लिए एक उपयुक्त और अनुपालन ढांचा प्रदान करती है। क्लाउड और बिग डेटा दोनों ही निवेश लागत को कम करते हुए एक कंपनी के मूल्य को बढ़ाने पर जोर देते हैं।





